堆内内存
Spark 1.6之后引入的统一内存管理机制,与静态内存管理的区别在于Storage和Execution共享同一块内存空间,可以动态占用对方的空闲区域
其中最重要的优化在于动态占用机制,其规则如下:
- 设定基本的Storage内存和Execution内存区域(spark.storage.storageFraction参数),该设定确定了双方各自拥有的空间的范围
- 双方的空间都不足时,则存储到硬盘,若己方空间不足而对方空余时,可借用对方的空间(存储空间不足是指不足以放下一个完整的 Block)
- Execution的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后”归还”借用的空间
- Storage的空间被对方占用后,无法让对方”归还”,因为需要考虑 Shuffle过程中的很多因素,实现起来较为复杂
动态内存占用机制
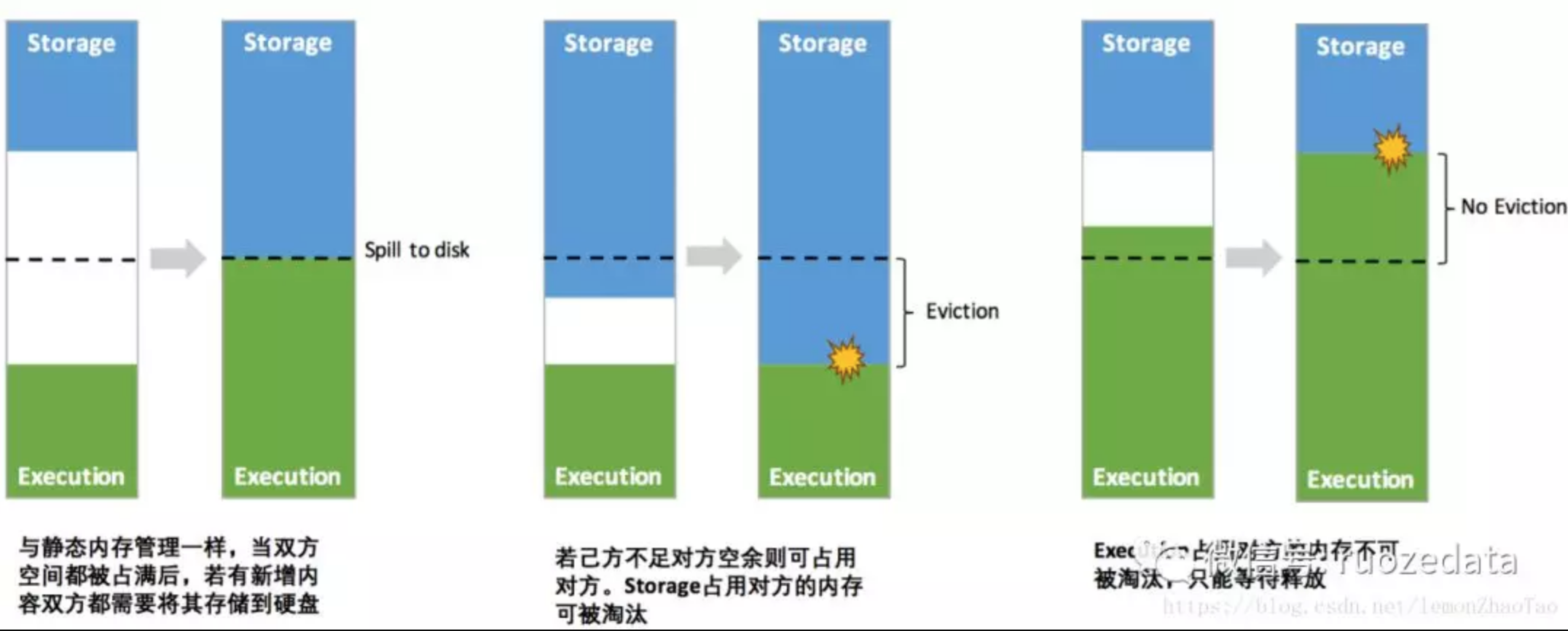
动态占用机制如下图所示:
凭借统一内存管理机制,Spark 在一定程度上提高了堆内和堆外内存资源的利用率,降低了开发者维护 Spark 内存的难度,但并不意味着开发者可以高枕无忧
譬如:如果Storage的空间太大或者说缓存的数据过多,反而会导致频繁的全量垃圾回收,降低任务执行时的性能,因为缓存的 RDD 数据通常都是长期驻留内存的。所以要想充分发挥 Spark 的性能,需要开发者进一步了解存储内存和执行内存各自的管理方式和实现原理
堆外内存
如下图所示,相较于静态内存管理,引入了动态占用机制

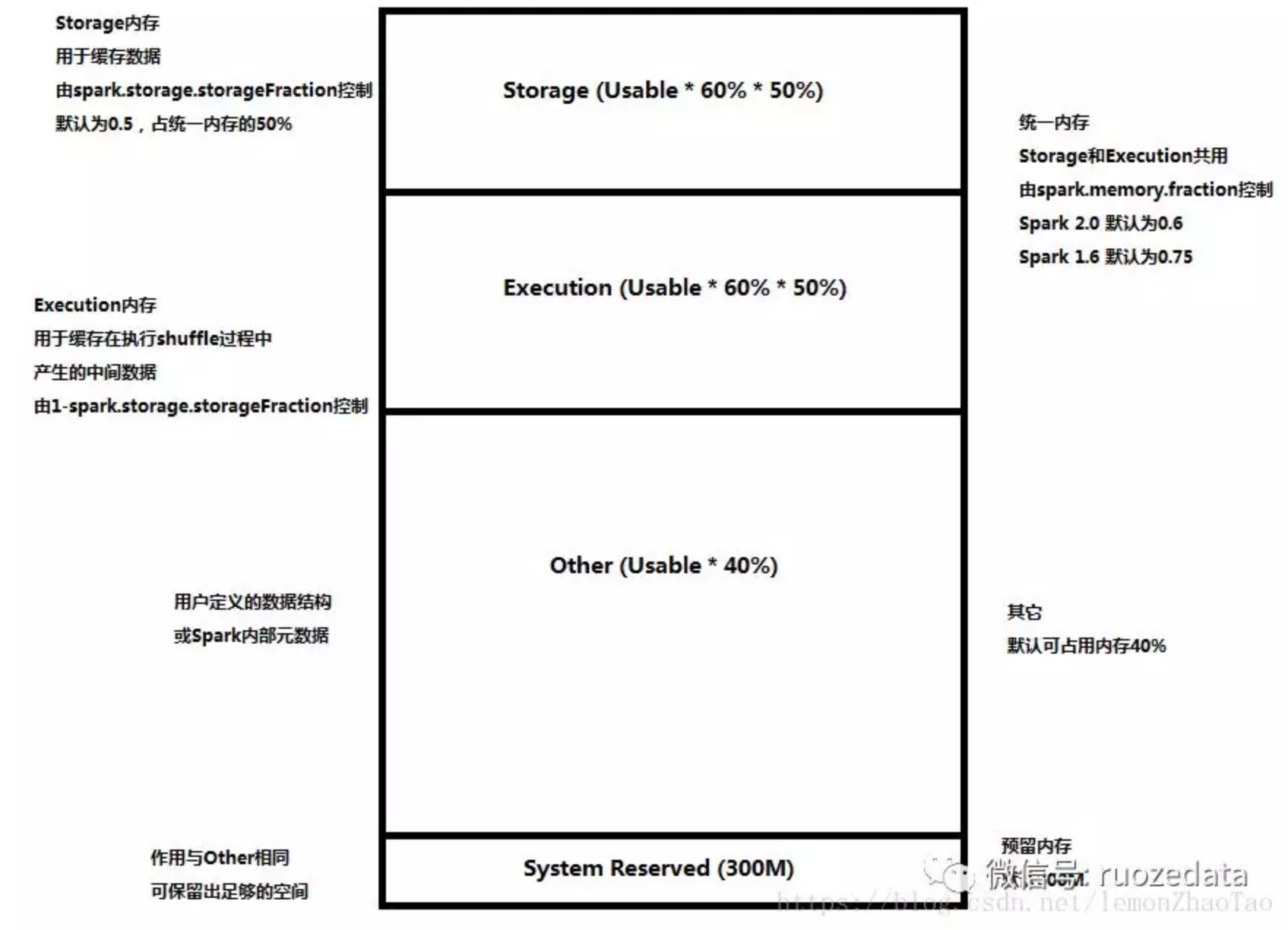
计算公式
spark从1.6版本以后,默认的内存管理方式就调整为统一内存管理模式
由UnifiedMemoryManager实现
Unified MemoryManagement模型,重点是打破运行内存和存储内存之间的界限,使spark在运行时,不同用途的内存之间可以实现互相的拆借
Reserved Memory
这部分内存是预留给系统使用,在1.6.1默认为300MB,这一部分内存不计算在Execution和Storage中;可通过spark.testing.reservedMemory进行设置;然后把实际可用内存减去这个reservedMemor得到usableMemory
ExecutionMemory 和 StorageMemory 会共享usableMemory * spark.memory.fraction(默认0.75)
注意:- 在Spark 1.6.1 中spark.memory.fraction默认为0.75
- 在Spark 2.2.0 中spark.memory.fraction默认为0.6
User Memory
分配Spark Memory剩余的内存,用户可以根据需要使用
在Spark 1.6.1中,默认占(Java Heap - Reserved Memory) * 0.25
在Spark 2.2.0中,默认占(Java Heap - Reserved Memory) * 0.4
Spark Memory
计算方式为:(Java Heap – ReservedMemory) * spark.memory.fraction
在Spark 1.6.1中,默认为(Java Heap - 300M) * 0.75
在Spark 2.2.0中,默认为(Java Heap - 300M) * 0.6
Spark Memory又分为Storage Memory和Execution Memory两部分
两个边界由spark.memory.storageFraction设定,默认为0.5
对比
相对于静态内存模型(即Storage和Execution相互隔离、彼此不可拆借),动态内存实现了存储和计算内存的动态拆借:
- 当计算内存超了,它会从空闲的存储内存中借一部分内存使用
- 存储内存不够用的时候,也会向空闲的计算内存中拆借
值得注意的地方是:
- 被借走用来执行运算的内存,在执行完任务之前是不会释放内存的
- 通俗的讲,运行任务会借存储的内存,但是它直到执行完以后才能归还内存
和动态内存相关的参数
spark.memory.fraction
1
2
3
4
5Spark 1.6.1 默认0.75,Spark 2.2.0 默认0.6
这个参数用来配置存储和计算内存占整个可用内存的比例
这个参数设置的越低,也就是存储和计算内存占可用的比例越低,就越可能频繁的发生内存的释放(将内存中的数据写磁盘或者直接丢弃掉)
反之,如果这个参数越高,发生释放内存的可能性就越小
这个参数的目的是在jvm中留下一部分空间用来保存spark内部数据,用户数据结构,并且防止对数据的错误预估可能造成OOM的风险,这就是Other部分spark.memory.storageFraction
1
默认 0.5;在统一内存中存储内存所占的比例,默认是0.5,如果使用的存储内存超过了这个范围,缓存的数据会被驱赶
spark.memory.useLegacyMode
1
2
3
4
5
6默认false;设置是否使用saprk1.5及以前遗留的内存管理模型,即静态内存模型,前面的文章介绍过这个,主要是设置以下几个参数:
spark.storage.memoryFraction
spark.storage.safetyFraction
spark.storage.unrollFraction
spark.shuffle.memoryFraction
spark.shuffle.safetyFraction
动态内存设计中的取舍
因为内存可以被Execution和Storage拆借,我们必须明确在这种机制下,当内存压力上升的时候,该如何进行取舍?
从三个角度进行分析:
- 倾向于优先释放计算内存
- 倾向于优先释放存储内存
- 不偏不倚,平等竞争
释放内存的代价
释放存储内存的代价取决于Storage Level.:
- 如果数据的存储level是MEMORY_ONLY的话代价最高,因为当你释放在内存中的数据的时候,你下次再复用的话只能重新计算了
- 如果数据的存储level是MEMORY_AND_DIS_SER的时候,释放内存的代价最低,因为这种方式,当内存不够的时候,它会将数据序列化后放在磁盘上,避免复用的时候再计算,唯一的开销在I/O
综述:
释放计算内存的代价不是很显而易见:
- 这里没有复用数据重计算的代价,因为计算内存中的任务数据会被移到硬盘,最后再归并起来(后面会有文章介绍到这点)
- 最近的spark版本将计算的中间数据进行压缩使得序列化的代价降到了最低
值得注意的是:
- 移到硬盘的数据总会再重新读回来
- 从存储内存移除的数据也许不会被用到,所以当没有重新计算的风险时,释放计算的内存要比释放存储内存的代价更高(假使计算内存部分刚好用于计算任务的时候)
实现复杂度
- 实现释放存储内存的策略很简单:我们只需要用目前的内存释放策略释放掉存储内存中的数据就好了
- 实现释放计算内存却相对来说很复杂
这里有2个释放计算内存的思路:
- 当运行任务要拆借存储内存的时候,给所有这些任务注册一个回调函数以便日后调这个函数来回收内存
- 协同投票来进行内存的释放
值得我们注意的一个地方是,以上无论哪种方式,都需要考虑一种特殊情况:
- 即如果我要释放正在运行的计算任务的内存,同时我们想要cache到存储内存的一部分数据恰巧是由这个计算任务产生的
- 此时,如果我们现在释放掉正在运行的任务的计算内存,就需要考虑在这种环境下会造成的饥饿情况:即生成cache的数据的计算任务没有足够的内存空间来跑出cache的数据,而一直处于饥饿状态(因为计算内存已经不够了,再释放计算内存更加不可取)
此外,我们还需要考虑:一旦我们释放掉计算内存,那么那些需要cache的数据应该怎么办?有2种方案:
- 最简单的方式就是等待,直到计算内存有足够的空闲,但是这样就可能会造成死锁,尤其是当新的数据块依赖于之前的计算内存中的数据块的时候
- 另一个可选的操作就是丢掉那些最新的正准备写入到磁盘中的块并且一旦当计算内存够了又马上加载回来。为了避免总是丢掉那些等待中的块,我们可以设置一个小的内存空间(比如堆内存的5%)去确保内存中至少有一定的比例的的数据块
综述:
所给的两种方法都会增加额外的复杂度,这两种方式在第一次的实现中都被排除了
综上目前看来,释放掉存储内存中的计算任务在实现上比较繁琐,目前暂不考虑
即计算内存借了存储内存用来计算任务,然后释放,这种不考虑;计算内存借来内存之后,是可以不还的
结论:
我们倾向于优先释放掉存储内存
即如果存储内存拆借了计算内存,当计算内存需要进行计算并且内存空间不足的时候,优先把计算内存中这部分被用来存储的内存释放掉
可选设计
1.设计方案
结合我们前面的描述,针对在内存压力下释放存储内存有以下几个可选设计:
设计1:释放存储内存数据块,完全平滑
计算和存储内存共享一片统一的区域,没有进行统一的划分
- 内存压力上升,优先释放掉存储内存部分中的数据
- 如果压力没有缓解,开始将计算内存中运行的任务数据进行溢写磁盘
设计2:释放存储内存数据块,静态存储空间预留,存储空间的大小是定死的
这种设计和1设计很像,不同的是会专门划分一个预留存储内存区域:在这个内存区域内,存储内存不会被释放,只有当存储内存超出这个预留区域,才会被释放(即超过50%了就被释放,当然50%为默认值)。这个参数由spark.memory.storageFraction(默认值为0.5,即计算和存储内存的分割线)配置
设计3:释放存储内存数据块,动态存储空间预留
这种设计于设计2很相似,但是存储空间的那一部分区域不再是静态设置的了,而是动态分配;这样设置带来的不同是计算内存可以尽可能借走存储内存中可用的部分,因为存储内存是动态分配的
结论:最终采用的的是设计3
2.各个方案的优劣
设计1被拒绝的原因
设计1不适合那些对cache内存重度依赖的saprk任务,因为设计1中只要内存压力上升就释放存储内存
设计2被拒绝的原因
设计2在很多情况下需要用户去设置存储内存中那部分最小的区域
另外无论我们设置一个具体值,只要它非0,那么计算内存最终也会达到一个上限,比如,如果我们将存储内存设置为0.6,那么有效的执行内存就是:- Spark 1.6.1 可用内存0.40.75
Spark 2.2.0 可用内存0.40.6
那么如果用户没有cache数据,或是cache的数据达不到设置的0.6,那么这种情况就又回到了静态内存模型那种情况,并没有改善什么
最终选择设计3的原因
设计3就避免了2中的问题只要存储内存有空余的情况,那么计算内存就可以借用
需要关注的问题是:
- 当计算内存已经使用了存储内存中的所有可用内存但是又需要cache数据的时候应该怎么处理
- 最早的版本中直接释放最新的block来避免引入执行驱赶策略(eviction策略,上述章节中有介绍)的复杂性
- 存储内存没有上限
- 计算内存没有上限
- 保障了存储空间有一个小的保留区域
